Abstract
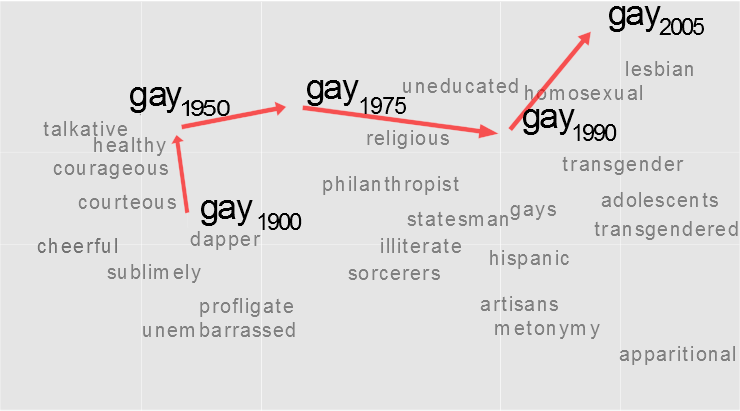
We propose a new computational approach for tracking and detecting statistically significant linguistic shifts in the meaning and usage of words. Such linguistic shifts are especially prevalent on the Internet, where the rapid exchange of ideas can quickly change a word’s meaning. Our meta-analysis approach constructs property time series of word usage, and then uses statistically sound change point detection algorithms to identify significant linguistic shifts.
We consider and analyze three approaches of increasing complexity to generate such linguistic property time series, the culmination of which uses distributional characteristics inferred from word co-occurrences. Using recently proposed deep neural language models, we first train vector representations of words for each time period. Second, we warp the vector spaces into one unified coordinate system. Finally, we construct a distance-based distributional time series for each word to track its linguistic displacement over time.
We demonstrate that our approach is scalable by tracking linguistic change across years of micro-blogging using Twitter, a decade of product reviews using a corpus of movie reviews from Amazon, and a century of written books using the Google Book-ngrams. Our analysis reveals interesting patterns of language usage change commensurate with each medium.
A copy of the paper is available here
Code
Langchangetrack
Langchangetrack is an implementation of the methods described in the paper as python package. The package is available here with sample usage instructions. The details are also available in our paper.
Summary of usage
The package contains implementations of the below general meta-algorithm:
- Time series construction: We model evolution of a word through time by constructing time series.
- Change point detection: We then analyze this time series to detect changepoints which are statistically significant.
Input The input is assumed to be a temporal corpus of text files (appropriately tokenized) to be present in a directory. In addition we assume list of words in a single text file that one is interested in tracking. This could just be the set of words in the common vocabulary of the temporal corpus.
Output The output consists of the significance scores for each word indicating when a change point was detected and its significance.
Sample commands and examples with detailed usage options are described at the package site.
Resources
Datasets and Resources
- Download the data sets used for evaluation here
- Coming soon: Conference Talk Presentation
Citing
Citing us
If you find our methods useful in your research, we ask that you cite the following paper:
@inproceedings{Kulkarni:langchange,
author = {Kulkarni,Vivek and Al-Rfou, Rami and Perozzi,Bryan and Skiena, Steven},
title = {Statistically Significant Detection of Linguistic Change},
booktitle = {Proceedings of the 24th International World Wide Web Conference},
series = {WWW '15},
year = {2015},
location = {Florence, Italy},
numpages = {11},
}